Dive into the world of online permissions and it quickly becomes clear: it’s all about the connections you hold. Imagine being at an upscale gala. It’s not just about your invitation card that gets you through the door. It’s about who you know inside, the conversations you’re a part of, and the circles you move in.
In the digital realm, it’s similar. Access isn’t always about direct permissions; it’s about the intricate web of relationships that you’re entangled in. Can you view this document? Well, it depends – are you linked to its creator, or part of the team that worked on it?
It’s this nuanced dance of relationships that defines relation-based authorization. Less of a straightforward checklist and more of a dynamic network of ties, it offers a richer, deeper layer to deciding “Who gets to do what?”.
TL;DR: We explored the foundational concepts of relation-based authorization models, tracing back to the roots in tech giants like Google. With the power of Ory Keto and Spring Boot, we crafted a hands-on example to bring the theory to life. Want to dive straight into the action? Check out our detailed hands-on integration: A Hands-on Integration of Ory Keto and Spring Boot.
The Google Zanzibar Paper and its Influence on Rapid Authorization Framework Development
In recent years, a notable event has had a profound influence on the world of authorization frameworks. This event was the release of the Google Zanzibar paper, a highly insightful document that details Google’s approach to scalable, efficient authorization.
Google’s Zanzibar system is a testament to the prowess of modern technology. According to the paper, Zanzibar handles access management for an astonishing number of resources - we’re talking trillions of objects - used by hundreds of millions of users. What makes these figures even more impressive is the wide array of client services that rely on Zanzibar. Renowned platforms like Google Maps, Google Drive, and YouTube, all depend on Zanzibar for their authorization needs.
But Zanzibar doesn’t just handle this enormous load, it does so rapidly and reliably. The system boasts a remarkable response time, with 95% of requests being handled within just 10 milliseconds and 99% within 20 milliseconds. On top of this, Zanzibar has proven its reliability, maintaining an exceptional availability rate of 99.999% over the past three years.
However, the impact of the Zanzibar paper extends beyond these impressive technical capabilities. The release of the paper pushed a flurry of development in the authorization realm, resulting in a variety of open-source projects and SaaS offerings inspired by Google’s Zanzibar, including Ory Keto, AuthZed, and OpenFGA.
But why has this paper sparked such a wave of development? The answer lies in a combination of factors:
- Scalability: As mentioned, Zanzibar’s ability to handle authorization for trillions of objects by hundreds of millions of users is awe-inspiring. As more businesses adopt microservices and cloud-native architectures, the need for scalable authorization solutions becomes increasingly pressing. Zanzibar offers a proven blueprint for achieving such scalability.
- Flexibility: The Zanzibar model, termed Global, Consistent Authorization System, is not tied to specific business logic or policies. This flexibility makes it broadly applicable across various domains and use cases, inspiring many to leverage it in their contexts.
- Efficiency: Efficiency in authorization is crucial. Zanzibar’s use of data sharding and re-sharding for optimal use of resources has been an inspiration for many developing authorization frameworks.
- Reliability: Google’s paper emphasizes Zanzibar’s ability to provide consistent authorization decisions, even in the face of network partitions and system failures. This high level of reliability is a key factor in Zanzibar’s appeal.
- Innovation: Finally, the Zanzibar paper represents a significant leap in the way we think about and implement authorization. Its innovative approach to handling access control at a massive scale has piqued the interest of many in the field, spurring them to explore and adopt similar strategies.
The widespread interest and rapid development sparked by the Zanzibar paper are testaments to its game-changing potential in the realm of scalable authorization. As we at SWCode embark on our journey to implement a scalable authorization architecture, we too are inspired by the lessons gleaned from Google’s Zanzibar.
Unpacking Zanzibar’s Relation-Tuple-Based Model
At the core of Google’s Zanzibar system is a surprisingly simple yet powerful model: relation tuples. A relation tuple is a small record that describes a relationship, in the form of namespace:object#relation@subject. In this format:
namespacerepresents the type of the object, such asdocumentorfolder.objectrefers to a unique identifier for a specific instance of that type, like a specific document ID or folder ID.relationrelation signifies the type of relationship between the object and the subject, such asownerorviewer.subjectcan either be a user or another relation tuple, allowing for complex, nested relationships.
For example, a relation tuple might look like this: document:readme#owner@user456, meaning that user456 is the owner of readme in the document namespace.
Expanding on this, the subject in a relation tuple doesn’t necessarily need to be a user. It could also be another relation tuple. This introduces the ability to create relationships between objects, as exemplified by document:readme#parent@folder:A, indicating that the folder A is the parent of the document readme.
By combining these simple elements, Zanzibar can describe complex hierarchical relationships and permissions across vast numbers of objects and users. This granularity of control is one of the key reasons for Zanzibar’s flexibility and scalability, and it’s a fundamental concept that has been adopted by Zanzibar-inspired frameworks mentioned before.
Expanding on this concept, Zanzibar’s relationships weave a structured graph connecting objects. Its strength lies in the straightforward approach: for authorization validation, Zanzibar merely verifies the presence of a certain relationship. Using our previous example, it would simply verify if there’s an owner connection between the document readme and user456. To dive deeper into this mechanism and gain a clearer understanding, continue to our next chapter where we dissect the Ory Keto framework, a system inspired by Zanzibar.
It’s worth noting that this explanation is somewhat simplified for clarity. The original Zanzibar paper is a scientific work and delves into greater theoretical depth, but the above should provide readers with a foundational understanding of the core concept.
Ory Keto
Ory Keto, written in Go, is an open-source authorization system that pivots around the concept of relation tuples, echoing the foundational principles of Google’s Zanzibar. Ory Keto is packaged as a standalone service, offering both HTTPS and gRPC APIs for seamless integration across diverse systems. Recognizing the varied deployment needs of organizations, Ory provides Keto both as a Software as a Service (SaaS) offering and a self-hosted solution, ensuring adaptability across different infrastructural requirements.
While conceptualizing Ory Keto, certain guiding principles and assumptions were maintained to ensure its efficacy:
- Simplicity in Management: The system was built on the hypothesis that no individual or team would dedicate their full time to configuring an authorization system.
- Intuitive Nature: Keto is designed to be self-explanatory, minimizing the learning curve and ensuring that users find the system approachable.
- Familiarity: By adhering to familiar paradigms and practices, Keto reduces the onboarding time for developers and system administrators.
- Ease of Modification: Any changes or updates to the authorization configurations can be carried out with high confidence, ensuring system stability.
- Editorial Support: Thanks to the Ory Permission Language, which is a subset of Typescript, Keto is compatible with numerous editors. This ensures users have the flexibility and familiarity in their choice of tools.
Core Concepts of Ory Keto
- Adoption of the Relation Tuple Model: Ory Keto adapts the Zanzibar-inspired relation tuples model. As we’ve previously elaborated, a relation tuple succinctly describes a relationship in a format like
namespace:object#relation@subject. Through these tuples, Ory Keto can express and evaluate intricate hierarchical relationships and permissions across a multitude of objects and users, ensuring a granular and fine-tuned access control mechanism. - Ory Permission Language (OPL): OPL, envisioned as a subset of TypeScript, is Ory Keto’s method to detail and evaluate policies within its framework. Despite the internal engine of Keto being rooted in Go, OPL offers developers a familiar TypeScript-like syntax to outline intricate authorization policies seamlessly and precisely.
OPL integrates namespaces and rules to aid in permission evaluations by exploring relations, though the actual tracing is managed by Keto internally. While Google Zanzibar’s model was framed scientifically for researchers and experts, Ory Keto uses TypeScript-based OPL, targeting a broader developer audience for a more user-friendly experience.
Ory Permission Language
In Ory Keto, defining namespaces and relations is at the heart of the model. Let’s illustrate this with a hands-on example featuring two namespaces: Document and User.
Within the Document namespace, a user is designated as either an owner, a viewer, or an editor of a document through specific relations.
The core of authorization revolves around permissions, such as view or edit, rather than checking relations like ‘owner’ or ‘editor’. The concrete permission is checked against the relationships. Within the Ory Permission Language, permissions are declared as functions inside the permits property of the corresponding namespace.
The code provided outlines a basic permission structure, which Keto subsequently processes to generate relation tuples internally.
class User implements Namespace {}
class Document implements Namespace {
related: {
owners: User[]
editors: User[]
viewers: User[]
}
permits = {
view: (ctx: Context): boolean =>
this.related.viewers.includes(ctx.subject) ||
this.related.editors.includes(ctx.subject) ||
this.related.owners.includes(ctx.subject)
}
}
Revisiting Jane with Ory Keto Relations
In our preceding discussions on Role-Based Access Control (RBAC), we introduced Jane, an auditor working for GlobeCorp. Jane was granted ‘readonly’ access to GlobeCorp’s financial data and held the admin role at EcoLife. This time around, let’s reframe Jane’s scenario using Ory Keto’s relation tuple framework.
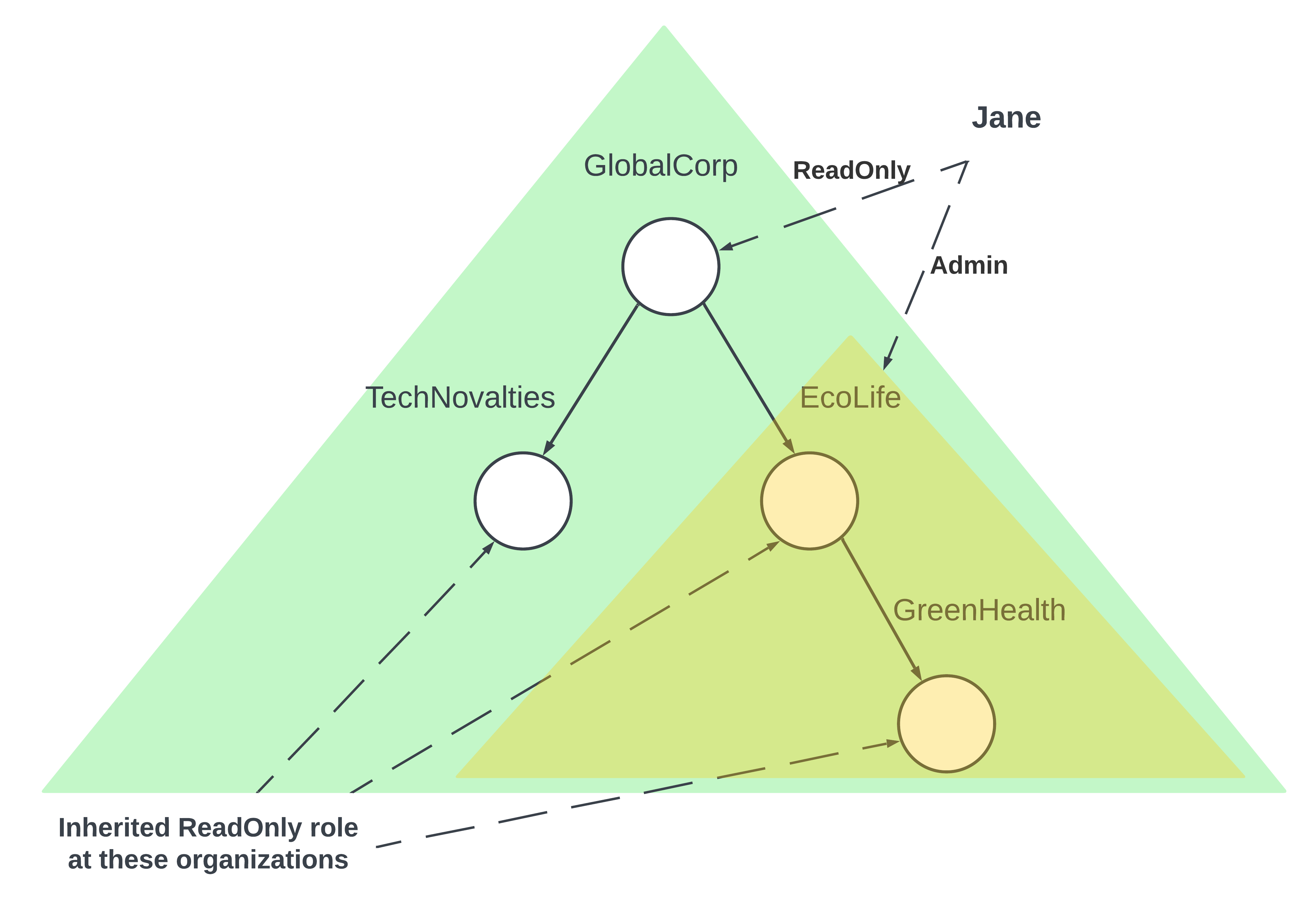
Here’s a quick recap:
- GlobeCorp is a global conglomerate
- TechNovelties and EcoLife are direct subsidiaries of GlobeCorp
- GreenHealth is a specialized vertical of EcoLife
In the OPL, all organizations will be clustered within a singular ‘Organization’ namespace, with functional dependencies illustrated using the ‘parents’ relations.
class Organization implements Namespace {
related: {
editors: User[]
viewers: User[]
parents: Organization[]
}
permits = {
view: (ctx: Context): boolean =>
this.related.viewers.includes(ctx.subject) ||
this.related.editors.includes(ctx.subject) ||
this.related.parents.traverse((p) => p.permits.view(ctx))
edit: (ctx: Context): boolean =>
this.related.editors.includes(ctx.subject) ||
this.related.parents.traverse((p) => p.permits.edit(ctx))
}
}
The diagram effectively visualizes Jane’s direct relations and how they cascade down the organization hierarchy using the parents relation in the context of Ory Keto’s permission system.
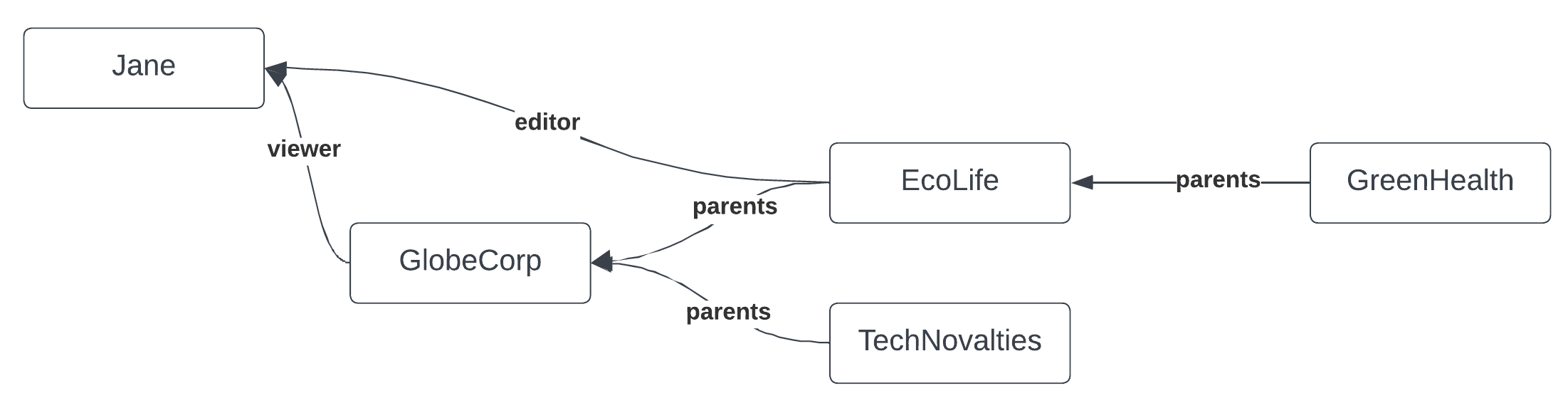
Given this arrangement and the provided OPL:
- Jane has a
viewerrelation to GlobeCorp, allowing her ‘readonly’ access to its data. This relationship extends hierarchically, meaning Jane can also view data of the companies that are subsidiaries or children of GlobeCorp due to the parents relation, which are TechNovelties and EcoLife. - Jane, due to her
editorsrelation with EcoLife, is endowed with edit access to its data. Leveraging the hierarchical structure, this access naturally extends to GreenHealth, EcoLife’s subsidiary.
Creating Relations in Ory Keto via REST API
Defining namespaces, relations, and permission rules forms the configuration phase in Ory Keto. Once this setup is complete, you can then dynamically create the actual relations to express relationships between various entities. This is achieved on-demand via REST API calls.
To illustrate, let’s define a relation that indicates EcoLife is a child organization of GlobalCorp. You can do this by making a PUT request as follows:
curl --location --request PUT 'http://localhost:4467/admin/relation-tuples' \
--header 'Content-Type: application/json' \
--data '{
"namespace": "Organization",
"object": "EcoLife",
"relation": "parents",
"subject_set": {
"namespace": "Organization",
"object": "GlobalCorp",
"relation": ""
}
}'
In this example, the relation parents for the object EcoLife points to GlobalCorp, indicating the hierarchical relationship between the two organizations.
Likewise, to establish a relationship between a user and an object, you would follow a similar approach.
For instance, if you want to specify that the user jane has a viewers relation to the organization EcoLife, you would craft a REST call as such:
curl --location --request PUT 'http://localhost:4467/admin/relation-tuples' \
--header 'Content-Type: application/json' \
--data '{
"namespace": "Organization",
"object": "GlobalCorp",
"relation": "viewers",
"subject_id": "jane"
}'
In the subsequent hands-on section, we provide a comprehensive configuration setup for Ory Keto, ensuring that you have all the tools and information at your disposal to effectively establish relations using the REST API.
A Hands-on Integration of Ory Keto and Spring Boot
Now that you’ve had a sip of the theory behind relation-based authorization, it’s time to roll up your sleeves and witness it in action. Our destination? A realistic scenario involving the integration of Ory Keto and Spring Boot.
Step 1: Cloning the Repository
To kick things off, we have laid out everything on a silver platter for you. By cloning our repository, you get access to a fully equipped application for our use case and docker-compose file:
- A PostgreSQL database to store your data.
- Keycloak, already set up with pre-configured users to handle authentication.
- Ory Keto, primed with an OPL definition, ensuring authorization processes are streamlined right from the get-go.
git clone https://github.com/sw-code/swcode-samples.git
cd swcode-samples/authz/authz-keto
Step 2: Explore the Code
Within the authz-keto directory, you’ll stumble upon our representation of the Jane and GlobalCorp scenario.
Remember Jane and her relationship with GlobalCorp and its sub-organizations? Yup, that’s what we’re bringing to life here.
Now, let’s dive deep into the heart of our application: the OrganizationController.
Two distinct endpoints are waiting to unveil the story of relation-based authorization in action.
- Viewing an Organization:
@GetMapping("/organizations/{organizationId}") @PreAuthorize("hasPermission(#organizationId, 'Organization', 'view')") fun getOrganization(@PathVariable organizationId: String): ResponseEntity<OrganizationDto>
The beacon guiding us here is the @PreAuthorize annotation.
Notice the “hasPermission” argument? This expression is the gatekeeper, determining if the user can view the specified Organization.
- Updating an Organization:
@PutMapping("/organizations/{organizationId}") @PreAuthorize("hasPermission(#organizationId, 'Organization', 'edit')") fun updateOrganization( @PathVariable organizationId: String, @RequestBody request: OrganizationUpdateDto ): ResponseEntity<OrganizationDto>
Again, the @PreAuthorize annotation stands guard. This time, however, it’s on the lookout for those who wish to edit the Organization.
But what brews behind this magical curtain of @PreAuthorize: The KetoPermissionEvaluator.
This component, a standard approach in Spring Security, implements the PermissionEvaluator interface and is instrumental in collaborating with Ory Keto to check permissions.
override fun hasPermission(
authentication: Authentication,
targetId: Serializable,
targetType: String,
permission: Any
): Boolean {
return ketoKetoClient.checkPermission(authentication.name, targetType, targetId as String, permission as String)
}
The hasPermission method takes in four arguments:
- authentication: This is an object provided by Spring Security, representing the current user’s authentication information.
- targetId: A Serializable ID, in this context, typically the identifier for a specific entity within the system.
- targetType: This string represents the type or category of the entity. In our case, it corresponds to the namespace in Ory Keto.
- permission: Represents the specific action or permission we want to check, such as
vieworedit.
Within the method, a call is made to ketoKetoClient.checkPermission(...), which, in turn, communicates with Ory Keto via REST API.
In essence, this method is asking Ory Keto: “Given this user and this specific entity in the provided namespace, do they have the specified permission?” The response is a Boolean, indicating either permission granted or denied.
An important detail to note is our choice of using the username directly from the authentication, instead of the typically recommended user ID. This decision was made purely for illustrative clarity. While in a production scenario, leveraging UUIDs as the subject would be the standard approach, here we’ve prioritized a straightforward demonstration to ensure a clear and uncomplicated understanding.
Step 3: Setup & Configuration
To initialize the necessary test data, we utilize the SampleDataInitializer class.
This class orchestrates the creation of our well-known GlobalCorp and its associated organizational hierarchies upon application launch.
Additionally, it ensures Jane is granted the appropriate access.
While user-to-organization relationships are forged directly within this class as part of sample data,
the relationships defining the organizational hierarchies (parents) are dynamically established.
Whenever a new organization is brought to life in our system, an OrganizationCreatedEvent is emitted.
This event is the catalyst, triggering the creation of parents relationships in Ory Keto when necessary.
Step 4: Launch & Play
Before launching the application, make sure you’ve initiated the necessary infrastructure using the supplied docker-compose file.
Once the application is up and running, test out the endpoints.
Within the repository, there’s a Postman collection tailor-made for this hands-on.
This collection includes everything you’ll need, from fetching a token from Keycloak for a user to making calls to our endpoints.
Start by trying to retrieve GlobalCorp’s data as Jane using GET /organizations/1.
Since Jane holds viewer permissions, this attempt will succeed.
But if you try to update this data? Expect a “Forbidden” response.
Remember, though, that Jane has editing rights for EcoLife.
This means you can update its information using PUT /organizations/3.
The same goes for its sub-organization, GreenHealth, accessible via PUT /organizations/4.
Certainly, you might’ve spotted endpoints like GET /organizations and POST /organizations that haven’t been enveloped in our authorization discussion yet.
These endpoints, unlike the others, don’t target a specific entity and thus require a slightly different approach.
However, fret not; the path forward with Keto will be smooth and intuitive.
The upcoming posts, where we’ll delve deeper into these aspects and navigate through other exciting challenges ahead.
Conclusion
In this comprehensive exploration, we dove into the fascinating world of relation-based authorization models. With its roots deeply embedded in Google’s Zanzibar, this approach presents a robust paradigm shift in how we perceive and implement permissions in the digital realm.
We unveiled a ready-to-use example coupling Spring Boot and Ory Keto, offering readers a tangible demonstration of these concepts in action. This elucidated how the various building blocks, when seamlessly integrated, can create an effective and secure authorization system.
As we step further into this domain, our journey is only just beginning. Looking ahead, there are several compelling challenges to address: understanding the dynamics of users and roles, managing blocking relations for exception handling, and tackling the demands of searching and filtering with permissions in mind.
The world of authorization is vast and ever-evolving, and we’re just scratching the surface. Stay with us as we delve deeper into its depths in our forthcoming discussions.